简介系统架构目录safwk_lite简介目录使用samgr_lite简介重要概念的介绍服务(Service),功能(Feature),对外接口(IUnknown)及实例接口(impl)注册过程IUnknown接口详解结构体分析宏定义分析三个函数的分析服务间通信Vector消息队列消息对象TaskPool小结跨进程通信参考文献
简介
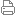
系统服务管理子系统实现系统服务框架,提供系统服务的启动、注册、查询功能,提供查询跨设备的分布式系统服务。
系统架构
目录
/foundation/distributedschedule
├── safwk # 系统服务框架模块
├── samgr # 系统服务管理模块
├── safwk_lite # 轻量foundation进程
├── samgr_lite # 轻量系统服务管理模块
这里我们介绍的是lite轻量级的系统服务管理。
safwk_lite
简介
safwk_lite模块负责提供基础服务运行的空进程。
目录
├── BUILD.gn
├── readme.md
├── LICENSE
├── src
└── main.c
使用
在foundation进程中添加服务,按照服务的模板写完服务后在BUILD.gn中添加依赖即可:
deps = [
"${aafwk_lite_path}/services/abilitymgr_lite:abilityms",
"${appexecfwk_lite_path}/services/bundlemgr_lite:bundlems",
"//base/hiviewdfx/hilog_lite/frameworks/featured:hilog_shared",
"//base/security/permission_lite/services/ipc_auth:ipc_auth_target",
"//base/security/permission_lite/services/pms:pms_target",
"//foundation/ability/dmsfwk_lite:dtbschedmgr",
"//foundation/distributedschedule/samgr_lite/samgr_server:server",
]
samgr_lite
简介
由于平台资源有限,且硬件平台多样,因此需要屏蔽不同硬件架构和平台资源的不同、以及运行形态的不同,提供统一化的系统服务开发框架。根据RISC-V、Cortex-M、Cortex-A不同硬件平台,分为两种硬件平台,以下简称M核、A核。
- M核:处理器架构为Cortex-M或同等处理能力的硬件平台,系统内存一般低于512KB,无文件系统或者仅提供一个可有限使用的轻量级文件系统,遵循CMSIS接口规范。
- A核:处理器架构为Cortex-A或同等处理能力的硬件平台,内存资源大于512KB,文件系统完善,可存储大量数据,遵循POSIX接口规范。
系统服务框架基于面向服务的架构,提供了服务开发、服务的子功能开发、对外接口的开发、以及多服务共进程、进程间服务调用等开发能力。其中:
- M核:包含服务开发、服务的子功能开发、对外接口的开发以及多服务共进程的开发框架。
- A核:在M核能力基础之上,包含了进程间服务调用、进程间服务调用权限控制、进程间服务接口的开发等能力。
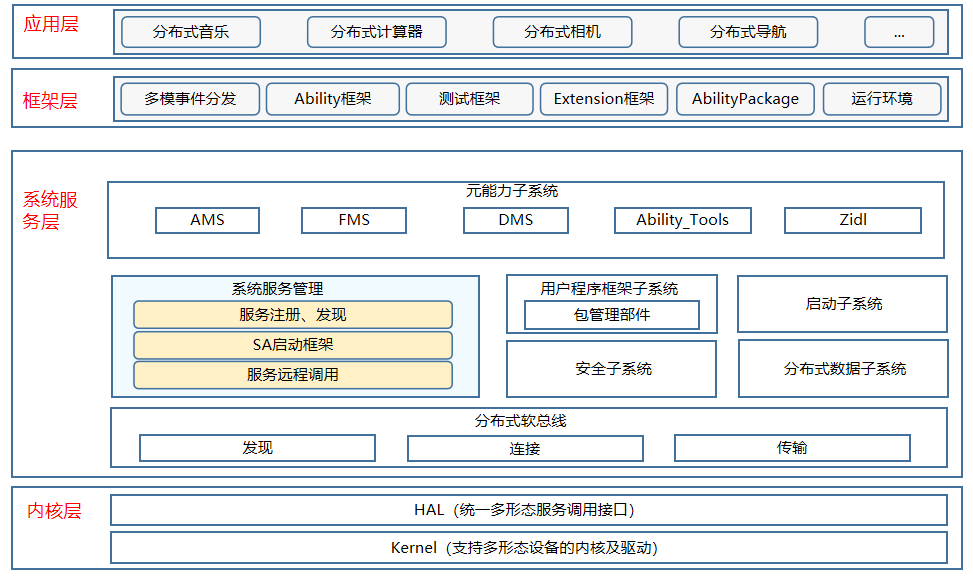
面向服务的架构:
- Provider:服务的提供者,为系统提供能力(对外接口)。
- Consumer:服务的消费者,调用服务提供的功能(对外接口)。
- Samgr:作为中介者,管理Provider提供的能力,同时帮助Consumer发现Provider的能力。
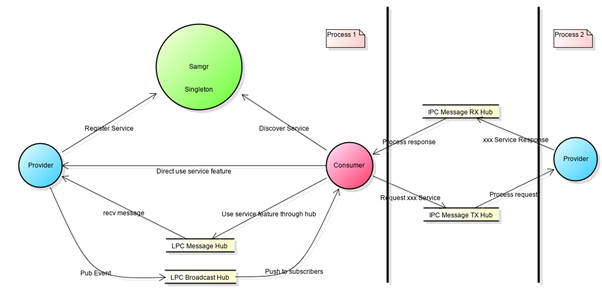
系统服务开发框架主体对象:
- SamgrLite:主要提供服务的注册与发现能力。
- Service:开发服务时,需要实现的服务的生命周期接口。
- Feature:开发功能时,需要实现的功能的生命周期接口。
- IUnknown:基于IUnknown开发服务或功能的对外接口。
- IClientProxy:IPC调用时,消费者的消息发送代理。
- IServerProxy:IPC调用时,开发者需要实现提供者的消息处理接口。
接口简介:
| 名称 |
描述 |
| interfaces/kits/samgr_lite/samgr |
M核和A核系统服务框架对外接口定义。 |
| interfaces/kits/samgr_lite/registry |
A核进程间服务调用的对外接口定义。 |
| interfaces/kits/samgr_lite/communication/broadcast |
M核和A核进程内事件广播服务的对外接口定义。 |
| services/samgr_lite/samgr/adapter |
POSIX和CMSIS接口适配层来屏蔽A核M核接口差异。 |
| services/samgr_lite/samgr/registry |
M核服务注册发现的桩函数。 |
| services/samgr_lite/samgr/source |
M核和A核系统服务开发框架基础代码。 |
| services/samgr_lite/samgr_client |
A核进程间服务调用的注册与发现。 |
| services/samgr_lite/samgr_server |
A核进程间服务调用的IPC地址管理和访问控制。 |
| services/samgr_lite/samgr_endpoint |
A核IPC通信消息收发包管理。 |
| services/samgr_lite/communication/broadcast |
M核和A核进程内事件广播服务。 |
约束
- 系统服务开发框架统一使用C开发。
- 同进程内服务间调用统一使用IUnknown接口对外,消息接口统一由IUnknown接口传递给本服务。
- 服务名和功能名必需使用常量字符串且长度小于16个字节。
- M核:系统依赖上bootstrap服务,在系统启动函数中调用OHOS_SystemInit()函数,此函数在foundation\distributedschedule\safwk_lite\src\main.c中,将跳转至foundation\distributedschedule\samgr_lite\samgr\source\samgr_lite.c中的SAMGR_Bootstrap()函数。
- A核:系统依赖samgr库,在main函数中调用SAMGR_Bootstrap()函数。
重要概念的介绍
系统服务管理的业务逻辑的实现围绕着三大概念展开,分别是服务(Service)、功能(Feature)和功能接口API(Iunknown)。下面将对这些概念进行讲解。
服务(Service),功能(Feature),对外接口(IUnknown)及实例接口(impl)
服务(Service)是业务逻辑的核心,是一组功能或操作的集合。下面的结构体定义了服务的相关函数指针,可以在foundation\distributedschedule\samgr_lite\interfaces\kits\samgr\service.h中看到。
struct Service {
const char *(*GetName)(Service *service); //获取服务名称
BOOL (*Initialize)(Service *service, Identity identity); //初始化服务
BOOL (*MessageHandle)(Service *service, Request *request); //处理服务的消息
TaskConfig (*GetTaskConfig)(Service *service); //获取服务的任务配置
};
一个服务可以拥有多个功能(Feature),功能是业务的执行单元。由各式各样的功能组合成一个完整的服务。下面的结构体定义了功能接口的相关函数指针。可以在foundation\distributedschedule\samgr_lite\interfaces\kits\samgr\feature.h中看到。
struct Feature {
const char *(*GetName)(Feature *feature); //获取功能名称
void (*OnInitialize)(Feature *feature, Service *parent, Identity identity); //初始化功能
void (*OnStop)(Feature *feature, Identity identity); //停止功能
BOOL (*OnMessage)(Feature *feature, Request *request); //处理功能消息
};
通过上述服务和功能的概念抽象出完整的业务逻辑模型。一个服务包含零个到多个功能。在OpenHarmony代码中,针对服务和功能的调用还提供了统一的对外接口(Iunknown)。可以在foundation\distributedschedule\samgr_lite\interfaces\kits\samgr\iunknown.h中看到。
struct IUnknown {
int (*QueryInterface)(IUnknown *iUnknown, int version, void **target);//查询指定版本的IUnknown接口的子类对象
int (*AddRef)(IUnknown *iUnknown); //添加引用计数
int (*Release)(IUnknown *iUnknown); //释放引用计数
};
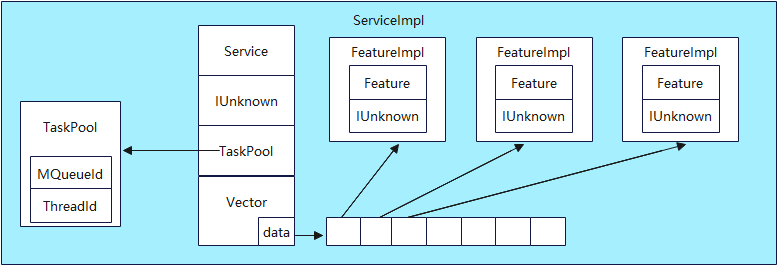
在后续服务和功能的注册、启动等过程中都是使用ServiceImpl和FeatureImpl,一个功能对应一个接口,作为一个功能的实例对象,一个服务至少向外提供一个API接口(当服务下面没有注册功能时,向外暴露defaultApi),也可以提供多个API接口(当服务下面注册多个功能时,每一个功能都有一个API接口),一个服务对应一个任务池。
struct FeatureImpl {
Feature *feature; //功能对象
IUnknown *iUnknown; //对外的接口
};
struct ServiceImpl {
Service *service; //服务对象
IUnknown *defaultApi; //默认的对外接口
TaskPool *taskPool; //绑定的任务池
Vector features; //已注册的FeatureImpl对象
int16 serviceId; //服务ID,位于g_samgrImpl的vector中的下标
uint8 inited; //服务所处的状态
Operations ops; //操作信息,记录一些运维信息
};
在ServiceImpl中,Vector的data指向一个FeatureImpl类型的指针数组,每个指针指向一个FeatureImpl对象。TaskPool指向一个TaskPool对象。图中只画出了部分重要字段。
任务池的绑定分为三种:
- 指向一个FeatureImpl类型的指针数组,每个指针指向一个FeatureImpl对象。TaskPool指向一个TaskPool对象。图中只画出了部分重要字段。
- SPECIFIED_TASK,为service绑定指定的任务池,遍历所有的ServiceImpl对象,查找相同任务配置的任务池,若找到则绑定,若未找到则创建新的任务池。
- SINGLE_TASK,根据任务配置,创建新的任务池并绑定。
注册过程
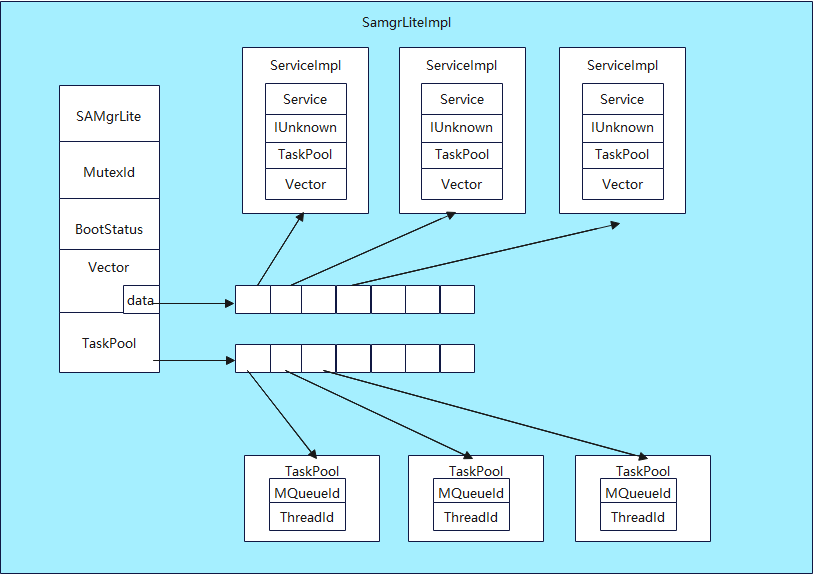
提到服务的注册我们还需要了解一个重要的数据结构SamgrLiteImpl,在代码中有一个由它定义的全局变量g_samgrImpl,这个全局变量维护了一系列的服务,也称为系统功能管理器(Samgr)。结构体定义如下,可以在foundation\distributedschedule\samgr_lite\samgr\source\samgr_lite_inner.h中看到:
struct SamgrLiteImpl {
SamgrLite vtbl; //SamgrLite类管理一些函数,用于注册和发现服务和功能
MutexId mutex; //互斥锁
BootStatus status; //系统功能管理器(samgr)的状态
Vector services; //已注册的ServiceImpl对象
TaskPool *sharedPool[MAX_POOL_NUM];//服务共享的任务池
};
注册的过程分为接口的注册、功能的注册和服务的注册。流程如下:
- Feature绑定IUnknown封装为FeatureImpl对象。(接口的注册)
- 将FeatureImpl对象添加到ServiceImpl的vector集合中。(功能的注册)
- 将ServiceImpl对象添加到SamgrLiteImpl的vector集合中。(服务的注册)
在SamgrLiteImpl中,Vector中的data指向一个ServiceImpl类型的指针数组,每个指针指向一个ServiceImpl对象。TaskPool指向一个TaskPool类型的指针数组,每个指针指向一个TaskPool,这一点与ServiceImpl中是不同的。图中只画出了部分重要字段。
IUnknown接口详解
iunknown是针对服务和功能的统一对外接口,头文件在foundation\distributedschedule\samgr_lite\interfaces\kits\samgr中,iunknown为系统功能的外部功能提供基类和默认实现。
IUnknown包含三个函数,分别是QueryInterface、AddRef、Release,QueryInterface是查询实现的接口类,需要注意查询完后要调用release解除引用,AddRef作用是增加引用计数,Release作用是减少引用计数。
引用计数牵涉到内存管理的概念,每增加1就代表当前组件被一个对象引用,每减少1就代表当前组件少一个引用者,当引用计数为0时,就代表已经没有对象使用它了,那么它的生命周期就到此结束,释放自己占用的资源。这种做法可以减少开发者的工作,有效减少内存泄漏情况的发生。
结构体分析
//结构体的声明,包含QueryInterface函数指针、AddRef函数指针、Release函数指针
struct IUnknown {
//查询指定版本接口的子类对象
int (*QueryInterface)(IUnknown *iUnknown, int version, void **target);
//添加引用计数
int (*AddRef)(IUnknown *iUnknown);
//释放对接口的引用
int (*Release)(IUnknown *iUnknown);
};
typedef struct IUnknownEntry {
//接口版本信息
uint16 ver;
//接口的引用计数。
int16 ref;
//IUnknown接口成员
IUnknown iUnknown;
} IUnknownEntry;
宏定义分析
//定义用于继承IUnknown接口的宏
//当开发IUnknown类的子类时,可以使用这个宏来继承IUnknown接口结构
#define INHERIT_IUNKNOWN \
int (*QueryInterface)(IUnknown *iUnknown, int version, void **target); \
int (*AddRef)(IUnknown *iUnknown); \
int (*Release)(IUnknown *iUnknown)
//定义用于继承实现IUnknown接口的类的宏
//当开发一个实现了IUnknown接口的类的子类时,可以使用这个宏继承IUnknown实现类的结构
#define INHERIT_IUNKNOWNENTRY(T) \
uint16 ver; \
int16 ref; \
T iUnknown
//定义初始化IUnknown接口的默认宏
//当创建IUnknown接口的子类对象时,可以使用此宏将IUnknown接口的成员初始化为默认值
#define DEFAULT_IUNKNOWN_IMPL \
.QueryInterface = IUNKNOWN_QueryInterface, \
.AddRef = IUNKNOWN_AddRef, \
.Release = IUNKNOWN_Release
//定义用于初始化实现IUnknown接口的类的宏。
//当创建实现IUnknown接口的类的子类对象时,可以使用这个宏将IUnknown实现类的成员初始化为默认值
#define IUNKNOWN_ENTRY_BEGIN(version) \
.ver = (version), \
.ref = 1, \
.iUnknown = { \
DEFAULT_IUNKNOWN_IMPL
#define IUNKNOWN_ENTRY_END }
三个函数的分析
查询接口信息QueryInterface
/*
函数功能:查询接口信息
函数参数:@iUnknown:iUnknown对象
@ver:版本号
@target:返回需要的IUnknown的子类类型
函数返回:成功 返回EC_SUCCESS,失败 返回EC_INVALID
函数描述:
1.查询指定版本的IUnknown接口。
2.在获得IUnknown接口对象后,函数调用者使用QueryInterface将该对象转换为所需的子类类型,内部将转换为调用者所需的子类类型。
*/
int IUNKNOWN_QueryInterface(IUnknown *iUnknown, int ver, void **target)
{
//参数检查
if (iUnknown == NULL || target == NULL) {
return EC_INVALID;
}
//返回IUnknownEntry类型的地址,通过iUnknown的地址推断
IUnknownEntry *entry = GET_OBJECT(iUnknown, IUnknownEntry, iUnknown);
//判断版本信息是否有效
if ((entry->ver & (uint16)ver) != ver) {
return EC_INVALID;
}
if (ver == OLD_VERSION &&
entry->ver != OLD_VERSION &&
(entry->ver & (uint16)DEFAULT_VERSION) != DEFAULT_VERSION) {
return EC_INVALID;
}
//作为返回值
*target = iUnknown;
//添加引用
iUnknown->AddRef(iUnknown);
return EC_SUCCESS;
}
增加引用AddRef
//增加iUnknown接口的引用计数,当重新实现QueryInterface函数时,需要在新的QueryInterface中调用该函数
int IUNKNOWN_AddRef(IUnknown *iUnknown)
{
if (iUnknown == NULL) {
return EC_INVALID;
}
//返回IUnknownEntry类型的地址,通过iUnknown的地址推断
IUnknownEntry *entry = GET_OBJECT(iUnknown, IUnknownEntry, iUnknown);
entry->ref++;//引用计数加1
return entry->ref;
}
释放引用Release
/*
函数功能:释放iUnknown对象的引用数
函数参数:@iUnknown:iUnknown对象
函数返回:成功 引用计数,失败 返回EC_INVALID
详细描述:
1.释放不再使用的IUnknown接口的引用
2.在系统提供的默认实现中,如果引用计数为0,则IUnknown接口对象和实现对象的内存不会被释放
*/
int IUNKNOWN_Release(IUnknown *iUnknown)
{
//参数检查
if (iUnknown == NULL) {
return EC_INVALID;
}
//转换为IUnknownEntry对象
IUnknownEntry *entry = GET_OBJECT(iUnknown, IUnknownEntry, iUnknown);
int ref = entry->ref - 1;//引用数-1
if (ref < 0) {
//存在异常
} else {
if (ref == 0) {
//iunknown对象的引用数为0,应删除
//在默认版本中,iunknown可能是全局变量,默认不删除。
} else {
entry->ref = ref;//更新计数
}
}
return ref;
}
服务间通信
OpenHarmony的业务逻辑,简单来说,就是将多个子功能注册到服务中,再把服务注册到全局系统功能管理器(Samgr)中,这样做就可以使一个服务包含零个或多个功能,而功能又绑定了对外接口,然后我们可以向暴露的接口发送消息,等服务执行特定的处理后再将响应消息发送回来。
之前已经介绍了Service、Feature和IUnknown以及它们的实例对象ServiceImpl、FeatureImpl和SamgrLiteImpl。在这部分将会对消息通信过程中重要的结构体进行分析,掌握这些重要结构就可以理解OpenHarmony的通信机制和交互过程。
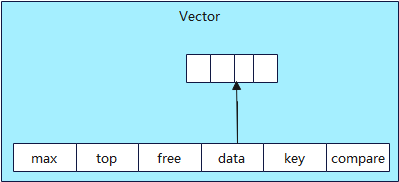
Vector
Vector是一种适用于数据量较小且需要动态拓展的开发场景的容器。它通过封装缓冲区,使用max,top和free三个参数来维护缓冲区的数据,同时定义了两个函数指针成员,一个用于获取Vector中数据的键值,另一个用于比较键值。Vector的结构定义如下,可以在foundation\distributedschedule\samgr_lite\interfaces\kits\samgr\common.h头文件中看到。
typedef struct SimpleVector {
int16 max; //可存储的最大数据记录数,即vector的容量。
int16 top; //已使用的数据记录数。
int16 free; //已释放的数据记录数。
void **data; //数据缓冲区,指向一块内存空间
//函数指针,指向将数据元素转换为键值的函数
VECTOR_Key key;
/**
* 函数指针,指向比较调用者提供的两个键值的函数
* 1 表示key1大于key2
* 0 表示key1等于key2
* -1 表示key1小于key2
*/
VECTOR_Compare compare;
} Vector;
Vector图示如下,仅画出部分字段。
消息队列
在OpenHarmony系统中实现了一个队列,主要是用于线程间通信,在进程间的通信是采用的共享内存的方式。队列是通过MQueueId字段来标识并使用的,它存储的是队列所占内存的首地址,所以它是不可以用于进程间通信的,因为不同的进程有不同的地址空间,当前进程MQueueId所标识的队列地址在其他进程中是无效的。队列的结构定义如下,可以在foundation\distributedschedule\samgr_lite\samgr\adapter\posix\lock_free_queue.h中看到。
struct LockFreeQueue {
uint32 write; //消息入队时写入的起始位置
uint32 read; //消息出队时读取的起始位置
uint32 itemSize; //每个元素的大小
uint32 totalSize; //总字节大小
uint8 buffer[0]; //数据缓冲区,这里起一个占位的作用,空间大小由调用者使用malloc()决定
};
OpenHarmony中的消息队列的存储空间是通过malloc()函数申请的,它所占用的空间布局如下图,仅画出部分字段。size是每个元素占用的字节数,count为元素个数。

消息对象
消息队列是线程间通信的重要结构。消息可以分为请求消息和响应消息,服务端接收到请求消息后会调用消息处理函数进行处理,然后将响应信息发送给请求者。请求消息是通过**Request封装的,响应消息是通过Response**封装的,它们的结构定义如下,可以在foundation\distributedschedule\samgr_lite\interfaces\kits\samgr\message.h中看到。
//请求消息结构体,用于承载请求数据
struct Request {
int16 msgId; //消息ID,标识当前消息的操作类型
int16 len; //标识data指向的缓冲区的长度
void *data; //指向一块缓冲区,保存请求发送的数据
/*
如果请求中传输的数据比较小,那么可以通过msgValue这个字段进行传输。
就不需要调用malloc()函数为data字段申请内存,这样可以提高消息发送的效率。
*/
uint32 msgValue; //消息值,也可以用于保存小数据
};
//响应消息结构体,用于承载响应数据
struct Response {
void *data; //指向一块缓冲区,保存响应的数据
int16 len; //标识data指向的缓冲区的长度
};
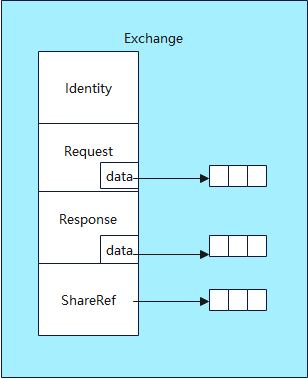
Exchange是真正传输的对象,它封装了Request和Response这两个重要的结构,并且用一个**Identity**类型的字段来标识目标服务和功能的地址。只要将消息放入目标服务和功能绑定的消息队列中即可完成消息的传输。Exchange和Identity结构体定义如下:
//消息通信时,消息队列中的元素对象
struct Exchange {
/*
exchange发往的目的服务或功能的地址
当客户端向服务端发送请求时,Identity是服务端的服务和功能的地址。
*/
Identity id; //目标服务或特性的标识
Request request; //请求消息体
Response response; //响应消息体
short type; //exchange对象类型,包括MSG_EXIT退出,MSG_ACK确认等
Handler handler; //异步响应或回调函数,用于消息的响应处理
uint32 *sharedRef; //用于共享请求和响应以节省内存
};
//用于标识服务和功能的地址信息
struct Identity {
int16 serviceId; //服务ID,即服务注册时,在samgr的vector中的下标
int16 featureId; //功能ID,即功能注册时,在服务的vector中的下标
MQueueId queueId; //服务和功能绑定的消息队列标识,本质上是队列的内存首地址
};
为了进一步节约内存空间,exchange中还有一个sharedRef字段,它的作用就是用来记录当前的exchange对象被引用的次数。以广播服务为例,当广播一条消息时,一个exchange对象就可能会被发送到多个消息队列中,由于数据是保存在堆中,通过data指针使用,所以传输的数据不需要拷贝到各个消息队列中,每一个消息队列只是保存data指针即可。所以通过sharedRef,我们可以知道data指针被引用了多少次,当引用数为0的时候就可以释放它指向的内存。Exchange图示如下,只画出部分字段:
TaskPool
上面已经介绍了vector(常用于服务和功能等的注册)、消息队列和消息对象,在这里我们接着分析任务池(Taskpool)在交互过程中扮演的角色。在服务实例(ServiceImpl)和系统功能管理实例(SamgrLiteImpl)中都有这个字段。略有不同的是服务实例中只指向一个任务池,而系统功能管理实例指向的是一个数组,数组的每一个元素又指向一个任务池。
这里使用的是任务池机制来负责消息队列中消息的接收和发送,任务池的底层维护了一组线程(可以是一个也可以是多个)每一个服务实例都会绑定一个任务池,而任务池又关联了一个消息队列,任务池中的线程负责从消息队列中读取消息并处理。服务实例只有绑定任务池后才会真正工作起来。任务池的结构定义如下,可以在foundation\distributedschedule\samgr_lite\samgr\source\task_manager.h中看到
typedef struct TaskPool TaskPool;
struct TaskPool {
MQueueId queueId; //消息队列ID,即队列的首地址
uint16 stackSize; //栈大小,用于配置线程的栈
uint8 priority; //任务的优先级,用于配置线程的优先级
uint8 size; //任务池的大小,维护的线程数
uint8 top; //标识tasks中的线程ID的个数
int8 ref; //引用数,引用数为0时释放任务池
ThreadId tasks[0]; //记录任务池下属的线程ID
};

小结
这里简单小结一下同一进程中不同服务间(线程间)的通信过程,先客户端产生请求数据并查询目标服务和功能的地址(Identity),然后从地址中拿到目标服务所绑定的消息队列ID(即消息队列首地址),将请求数据封装到exchange对象中,并修改它Identity字段中消息队列ID,改为当前客户端所绑定的消息队列ID,然后放入目标消息队列中。将exchange对象Identity的消息队列ID改为客户端的Id的原因是,只有这样,服务端在处理完这条消息时才知道应该把响应信息发送到哪个消息队列中。服务端处理完消息队列中接收的请求数据后,将响应信息填充到这个exchange对象中,并发送到Identity字段记录的消息队列ID(客户端绑定的消息队列)中。至此,线程间的交互就已完成。
跨进程通信
endpoint是当前进程与其他进程通信的进出口,所有进程间通信的交互都要经过它。每一个endpoint都有一个SvcIdentity字段来唯一标识当前进程的通信地址。当本进程的endpoint知道目标进程的endpoint地址后,就可以向它发送消息,完成进程间的交互。这里需要有一个知道所有endpoint通信地址的管理器来帮助发现目的进程的endpoint地址。在OpenHarmony的代码中指定了一个固定的SvcIdentity地址,作为公开的通信地址,我们把绑定这个地址的endpoint称为主endpoint或知名endpoint。所有的endpoint都要向这个主endpoint注册自己的通信地址。当本进程的endpoint需要向目的进程发送消息时,就可以向主endpoint查询目的进程的通信地址,有了地址以后就可以进行通信了。它的结构定义如下,可以在foundation\distributedschedule\samgr_lite\samgr_endpoint\source\endpoint.h中看到。
//当前进程和其他进程间通信的通信端点
struct Endpoint {
const char *name; //端点名称
IpcContext *context; //ipc上下文
//作为当前进程中服务和功能与其他进程间通信的桥梁,充当查找指定服务时的路由功能
Vector routers; //routers中保存的是router对象
ThreadId boss; //主线程,用于接收其他进程发出的消息
uint32 deadId;
int running; //标识endpoint的启用状态
SvcIdentity identity; //endpoint的身份标识,作为当前进程对外暴露的通信地址
RegisterEndpoint registerEP;//指向注册通信端点函数的指针
TokenBucket bucket; //令牌桶,作为消息接收和处理的流控机制
};
在针对代码的分析中,发现SvcIdentity的一个作用就是通过handle字段唯一标识进程的通信地址。
这里做一个场景假设。1号进程创建并初始化了主endpoint,2号进程刚启动。
首先2号进程先创建和初始化一个endpoint,称为IPC Client,然后向主endpoint发送注册消息,内核会在消息中填充2号进程的进程号(pid)、线程号(tid)和用户号(uid)。然后主endpoint从共享内存中读取到这条消息,会根据线程号tid产生唯一的handle标识,然后将pid、uid和handle保存到pidhandle中,然后将handle作为响应消息发送给2号线程。
自此2号进程的endpoint就成功注册,并得到了唯一的handle值,它作为当前进程的全局唯一标识。通过这个handle值可以唯一定位到一个进程。现在我们已经可以定位到指定进程了,但是OpenHarmony系统业务的执行是通过服务来完成的,所以我们还需要知道如何定位到进程中的服务和功能。这就是SvcIdentity的第二个作用,通过token字段定位进程内的服务和功能。token值的产生就涉及到进程内服务和功能的注册了。
在客户端进程中有一个全局变量g_remoteRegister,它维护了当前进程对外的endpoint。而endpoint中有一个vector类型的字段,名为routers。它维护了一系列router对象,每一个router对象都一一对应一个服务和功能。所以也可以称它为“路由表项”,通过它可以唯一定位指定的服务和功能。将服务和功能到endpoint的routers中作为一个“路由表项”,而它的下标就是SvcIdentity的token值。
//作为进程间的通信地址
typedef struct {
uint32_t handle; //当endpoint注册后,主endpoint会为它生成一个全局唯一的handle标识
uint32_t token; //标识服务和功能在路由表中的表项下标
uint32_t cookie;
#ifdef __LINUX__
IpcContext* ipcContext; //在linux下才有这个字段,进程通信的上下文
#endif
} SvcIdentity;
//用于标识endpoint和进程的关系
struct PidHandle {
pid_t pid; //进程ID
uid_t uid; //用户ID
uint32 handle; //向主endpoint注册后得到的唯一标识
uint32 deadId;
};
//路由表项,在进程间通信时,充当服务发现的路由功能
typedef struct Router
{
//这个字段用于在路由表中查找指定路由项时的key值
SaName saName; //标识服务名称和功能名称
//通过这个字段就可以定位到进程内部指定的服务、功能和消息队列
Identity identity; //标识服务名称、功能名称和消息队列
IServerProxy *proxy; //进程间通信的服务端代理接口
PolicyTrans *policy; //访问策略,做权限控制
uint32 policyNum; //访问策略的总数
} Router;
参考文献
[1] 轻量型系统服务管理部件.https://gitee.com/openharmony/systemabilitymgr_samgr_lite
[2] 轻量型系统服务框架部件.https://gitee.com/openharmony/systemabilitymgr_safwk_lite